
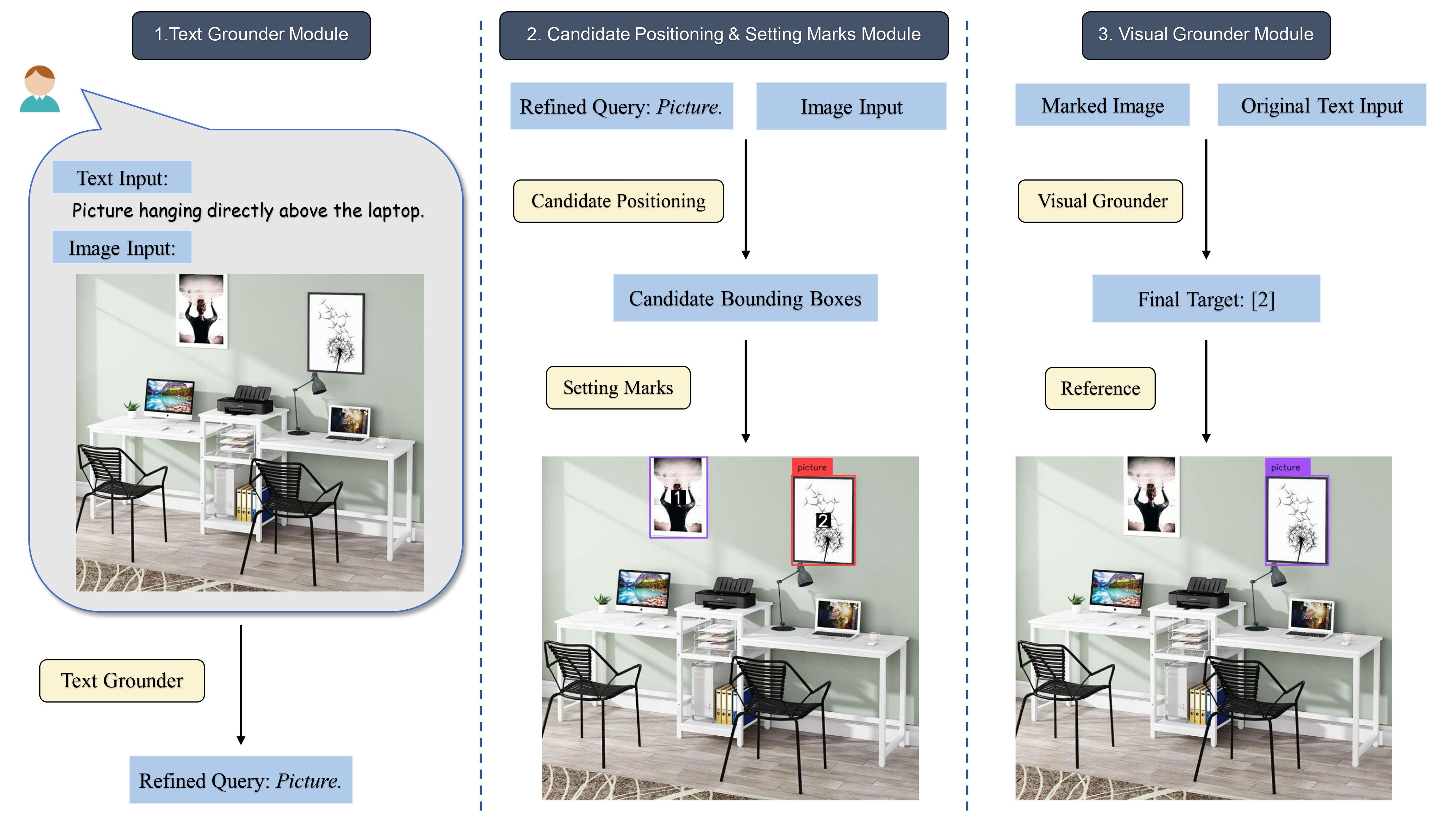
Query: a giraffe in between two other giraffes.

(a) Grounding DINO

(b) LLM-Optic
Query: a giraffe in between two other giraffes.

(a) Grounding DINO

(b) LLM-Optic
Query: a giraffe in between two other giraffes.
(a) Grounding DINO

(b) LLM-Optic
Query: a giraffe in between two other giraffes.

(a) Grounding DINO

(b) LLM-Optic
Query: a giraffe in between two other giraffes.

(a) Grounding DINO

(b) LLM-Optic
Query: a giraffe in between two other giraffes.

(a) Grounding DINO

(b) LLM-Optic
Query: a giraffe in between two other giraffes.

(a) Grounding DINO

(b) LLM-Optic